My crazy solution for the unread emails mess
04 Jun 2017In the middle of my fifth year high school exams, I finally decided I had to deal with the problem below:
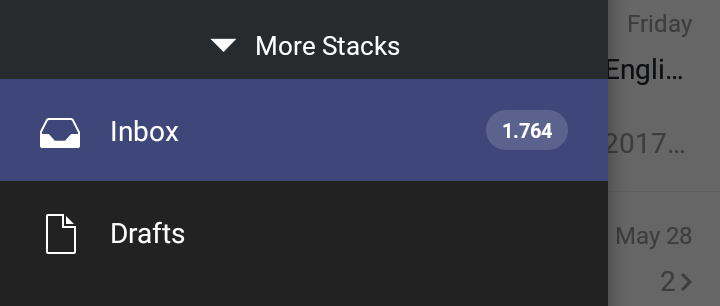
(and I know there are some of you out there with even bigger unread counters).
The thing is, I’ve been using that Gmail address in the past to subscribe to a lot of websites, forums, services etc… so it has always been full of newsletters, updates, forum summaries, and other stuff I don’t really care about. You may then ask: can’t you simply delete all the unread emails? Actually, the problem is I was so stupid I used that email account also for more important stuff like school lessons material, PayPal (and so payment receipts), eBay and Amazon, important work messages, etc… Besides that I discovered there is a good amount of unread “spam” emails that I would actually want to read before deleting them. A few newsletters from Silicon Labs, ST or Sparkfun as well as a couple of service updates from Nylas and other companies, for example. So I decided that a massive removal of all of them was not feasible.
Well sure, I could go through all of them and manually delete the ones I didn’t care about while reading the other ones but… As soon as I started doing that, I realized it was really boring, because it was a really repetitive task.
So what?
Introducing: MailCruncher (I know, I know… I put together this name using the first two words I came up with in that moment).
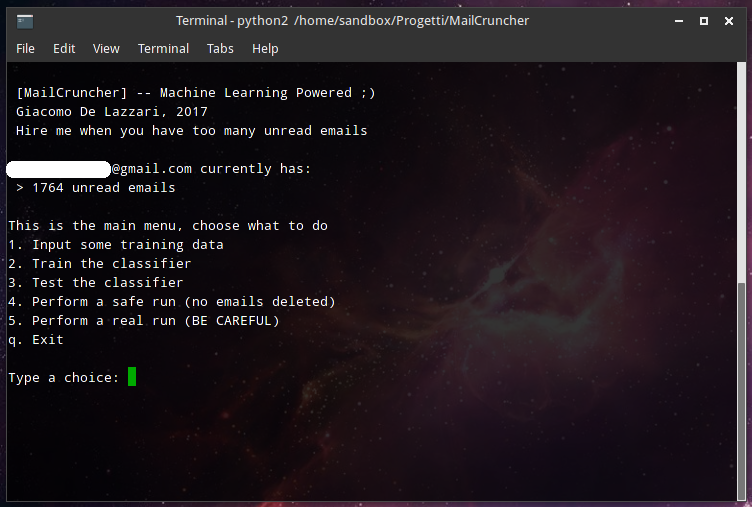
Name of the software apart, let’s dive in. This is what happens when you give someone like me libraries like NLTK and scikit-learn. You should already guess that the idea behind is to use the content (and other metadata) of the emails as features for a machine learning classifier, that tries to predict whether or not an unread email should be deleted.
First off, it goes without saying we need:
- A programming language
- A way to interface with our Gmail mailbox
- Some time to write the script
The answers for these points are:
- Python (because why not)
- https://github.com/charlierguo/gmail (thanks a lot to @charlierguo)
- Between midnight and 3AM = free time
Our data source is our inbox and we will be frequently fetching messages from it, we’ll also often end up querying for the same message multiple times. So, let’s make a quick class to handle our mailbox while caching to disk all the stuff we download:
class GmailAccount:
def __init__(self, login, password):
self.g = gmail.login(login, password)
self.dbname = login.split('@')[0] + ".json"
self.db = readJSON(self.dbname)
if self.db is None:
self.db = {}
self.writeDB()
def writeDB(self):
writeJSON(self.db, self.dbname)
# Convert from gmail.Message obj to Python dict
def mailToDictionary(self, mail):
...
# Convert from Python dict to gmail.Message obj
def dictionaryToMail(self, uid, d):
...
def insertIntoDB(self, emails, force=False):
for mail in emails:
if (...):
self.db[mail.uid] = self.mailToDictionary(mail)
self.writeDB()
def getUnreadInbox(self):
unread = self.g.inbox().mail(unread=True)
self.insertIntoDB(unread, force=False)
return unread
def fetchByUID(self, uid, update_db=True):
if uid in self.db and self.db[uid]['fetched'] == True:
return self.dictionaryToMail(uid, self.db[uid])
mail = gmail.Message(self.g.inbox(), uid)
try:
mail.fetch()
if update_db == True:
self.insertIntoDB([mail], force=False)
return mail
except:
return None
def getMail(self, uid, auto_fetch=True):
if not uid in self.db:
return None
if self.db[uid]['fetched'] == False:
if auto_fetch == True:
return self.fetchByUID(uid, update_db=True)
else:
return self.dictionaryToMail(uid, self.db[uid])
else:
return self.dictionaryToMail(uid, self.db[uid])(In case you’re wondering: Yes, I’m using JSON files as databases, and I’m not proud of that. But it works, and it’s very straightforward with Python)
Then we need a way to generate some training data for our classifier. I decided to randomly fetch some unread messages from the inbox and to present them to the user (me) asking for an action in that case. So I made a couple of functions to do that:
def fetchRandom(current_database, account, emails, numb=5):
def existsUID(elements, uid):
...
fetched = []
while len(fetched) < num:
try:
selected = emails[randint(0, len(emails) - 1)]
if existsUID(fetched, selected.uid) == True: continue
if selected.uid in current_database: continue
selected = account.getMail(selected.uid)
if selected.fr is None: continue
fetched.append(selected)
except:
continue
return fetched
def askLabels(emails):
labels = []
for mail in emails:
... # Show message on screen
label = raw_input("Would you keep an email like this? ")
if label == 'y':
labels.append(True)
elif label == 'quit':
break
else:
labels.append(False)
return labelsAnd the result is quite pleasing:
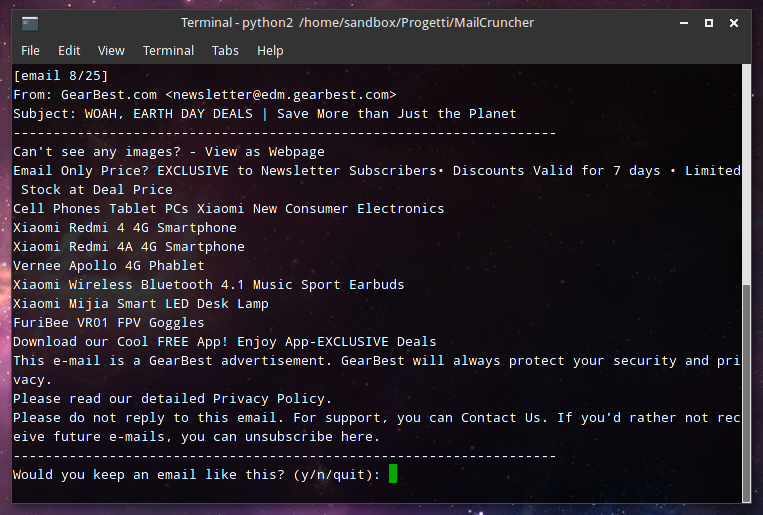
Moving on, we need to extract useful stuff from the messages and store this data along with the labels that the user inserted. We need to generate a kind of “blob” of data. I decided to use the mail content (both from the body and the HTML of the message - to be honest I don’t know the difference, but the gmail library I used works like this) along with the sender address, sender name and the mail subject. We also need to stem the text (i.e. removing all the punctuation and keeping the root of each work, to simplify our data). Also, because my emails are both in Italian and English, I need a way to identify the language and stem the text accordingly.
NLTK helps a lot here:
def detect_language(text):
languages_ratios = {}
tokens = wordpunct_tokenize(text)
words = [word.lower() for word in tokens]
for language in stopwords.fileids():
stopwords_set = set(stopwords.words(language))
words_set = set(words)
common_elements = words_set.intersection(stopwords_set)
# language "score"
languages_ratios[language] = len(common_elements)
return max(languages_ratios, key=languages_ratios.get)
def stemText(text, language):
... # remove punctuation
words = text.split()
stemmer = SnowballStemmer(language)
stemmedText = ""
for word in words:
if len(word) > 0:
stemmedText += stemmer.stem(word) + " "
return stemmedText
def genMailBlob(mail):
blob = ""
if mail.body is not None:
if any(t in mail.body for t in tags):
body_text = clean_html(mail.body)
language = detect_language(body_text)
blob += stemText(body_text, language)
else:
language = detect_language(mail.body)
blob += stemText(mail.body, language)
if mail.html is not None:
html_text = clean_html(mail.html)
html_lang = detect_language(html_text)
blob += ' ' + stemText(html_text, html_lang)
if mail.subject is not None:
blob += ' ' + stemText(mail.subject, language)
blob += ' ' + stemText(mail.fr, 'english')
blob += ' ' + mail.fr.split('<')[-1].replace('>', '')
return blobAn example blob will be something very funny like this:
hey giacomo de i m not sure if you receiv my last email but i want to check as i didn t want you to miss out on totalvpn s biggest ever sale right now you can get totalvpn at 80 off the regular price that mean a total unrestrict internet access to previous block tv show and most import ultim internet privaci and secur all from onli 1 99 mo all you have to do to take advantag of this offer is click this link and complet the quick checkout process let me know if there is anyth els i can do for you best kevin account manag totalvpn to unsubscrib from these email pleas go to http track totalvpn com s zhgp899gf6blfid msng dlv 1469887062 hrfh3xns email hey giacomo de i m not sure if you receiv my last email but i want to check as i didn t want you to miss out on totalvpn s biggest ever sale right now you can get totalvpn at 80 off the regular price click here now to take advantag of this 80 discount that mean a total unrestrict internet access to previous block tv show and most import ultim internet privaci and secur all from onli 1 99 mo let me know if there is anyth els i can do for you best kevin bennett account manag totalvpn if you wish to stop receiv this type of email from totalvpn staff pleas unsubscrib here giacomo de get a 80 discount today totalvpn sale totalvpn com sales@totalvpn.com
Yeah. Actually, we don’t care how messy our blob is, we just care about the amount and quality of the data that it contains. After some code to save all the training data to a local (obviously JSON) database, we can write some code to train a classifier. I used a SDGClassifier from scikit-learn, which by default uses a support vector machine (SVM) and trains it with a gradient descend algorithm. I choose that specific classifier because I think it works well with text classification. Maybe I should try with a Neural Network, but I doubt a NN will be any better in terms of accuracy (it will probably just be slower).
To train a classifier on a bunch of text, the most common way is to apply the bag of words operation, and then calculate the frequency of each word. To cut a long story short, we simply count how many times a word appears in the text and, when we have each word’s count, we normalize the values which leaves us with the frequency of each word appearing in the text. This means that our classifier must have as many inputs as the number of different and unique words in all our training database. That’s also why we “stemmed” the text before: if we didn’t, our dictionary size would have skyrocketed pretty soon.
So, this is our training code:
def train(database, samples_percentage=0.85):
data = []
target = []
samples = int(len(database) * samples_percentage)
for mailid in database:
mail = database[mailid]
data.append(mail['blob'])
target.append(int(mail['keep']))
clf = SGDClassifier(loss='modified_huber',
penalty='l2',
alpha=1e-3,
n_iter=5,
random_state=randint(0, 1000)
)
cv = CountVectorizer(stop_words='english')
tfidf = TfidfTransformer()
wordCount = cv.fit_transform(data)
wordFrequency = tfidf.fit_transform(wordCount)
clf.fit(wordFrequency[0:samples], target[0:samples])And, to see how well our classifier is performing, I wrote some testing code that both goes through the entire labeled database, but also just on the samples not considered in the training process (15% of them, accordingly to the code above). So we can check if it’s any good at predicting the fate of emails it has never seen before. Look at that!
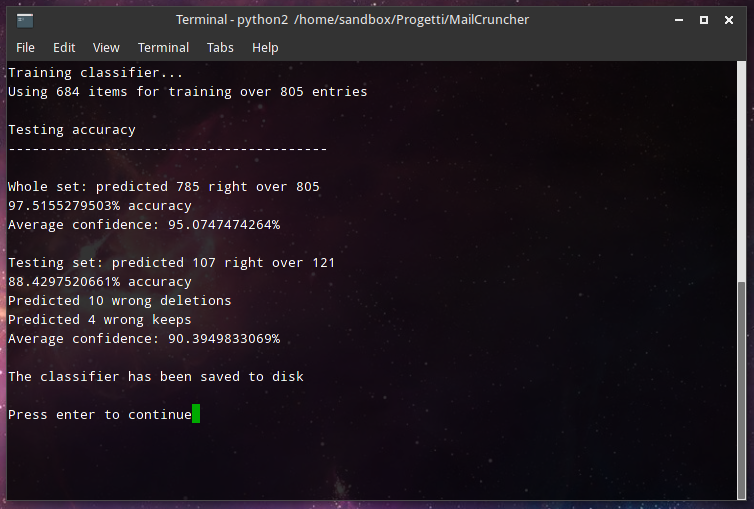 We have an 88% accuracy on our test dataset, that is pretty good in my opinion!
(especially considering I have a massive training set with probably a few errors in it).
The classifier also seems very confident with its decisions, in fact the average confidence
is around 90%.
We have an 88% accuracy on our test dataset, that is pretty good in my opinion!
(especially considering I have a massive training set with probably a few errors in it).
The classifier also seems very confident with its decisions, in fact the average confidence
is around 90%.
Let’s finally implement the “safe run” and “real run” options. They works almost the same way, the only difference is that the first one doesn’t really delete the emails but just shows on the screen what it would have deleted. It’s a sort of “preview” operation.
No code this time, because I think it’s quite simple how I implemented that. In order of execution, we simply need to:
- Get all our unread emails
- Generate the text blob for each of them
- Feed the blob through our classifier (after the bag of words and frequencies calculation)
- Understand the result of the classifier (i.e. should we delete the message or not? Is the classifier confident enough of its decision?)
- Delete emails accordingly
- Profit
This is a screenshot of a sample safe run:
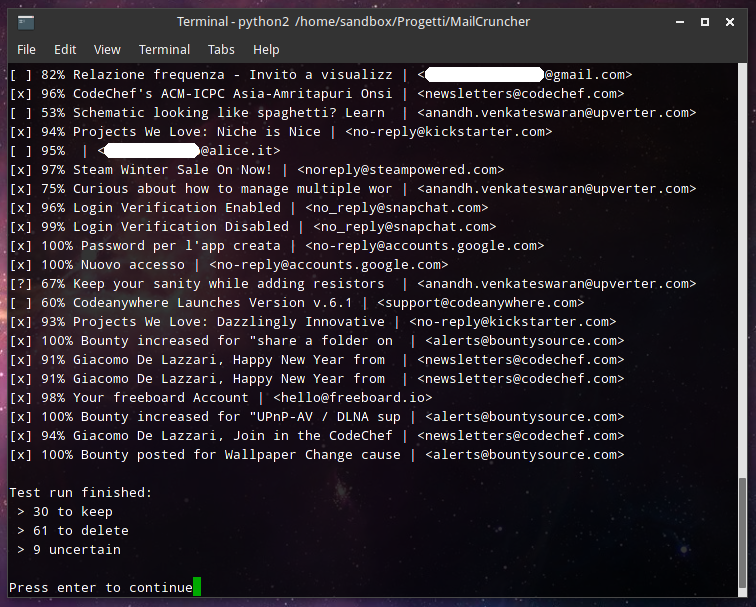
You obviously don’t know the criteria I taught the software to use when classifying the emails, but trust me if I tell you that it’s figuring out its decision really well. I’m surprised by its accuracy. For example you can see that the messages it is keeping are the ones from friends, and it’s also keeping a couple of newsletter it thinks would be interesting for me to read (and it guessed right). There’s also a newsletter it is uncertain about, and that means it is actually judging based on the content of the messages and not based on the sender or the subject. That’s pretty amazing, isn’t it?
The final touch was to create a main menu (the one in the first picture) and to make a little configuration wizard to ask the user (just the first time) its login details. I also added a feature that labels the emails that the classifier is uncertain about with an “Uncertain” label, so they end up in a separate folder of your mailbox and you can manually check them if you want.
Overall, the result is quite pleasing in my opinion. I’m really satisfied, and it was also a lot of fun creating this tool. And, obviously, my inbox is now much cleaner: in fact over a total of ~1750 unread emails just ~250 were kept.
I hope this was interesting and you learned something from this (pretty long) post. You can checkout the final code on GitHub here, where you’ll also find the instructions on how to run it.